






























New to KubeDB? Please start here.
The Importance of Replication in FerretDB
Scaling Read Operations
As applications grow, read-heavy workloads can slow down a single database. Replication helps by distributing queries across multiple instances, improving performance and reducing latency. This makes it easier to scale your FerretDB setup and maintain fast access to data.
Enhancing Availability
Replication increases fault tolerance by allowing your app to continue running from a replica if the primary database fails. If one replica goes down, traffic can be rerouted to others, ensuring uptime. In case of a failure, a replica can take over as the new primary, maintaining continuous operations.
FerretDB Replication
FerretDB stores data using PostgreSQL along with the DocumentDB extension and handles replication through WAL (Write-Ahead Logging) streaming. In this method, all database changes are first recorded in a log before they’re written to the main data files. Other forms of replication, like logical replication, often aren’t suitable because the replica would need elevated privileges—such as the ability to create schemas or tables—which aren’t always available.
A replication setup typically consists of:
Primary node: The main server that processes all writes.
Replica node: A secondary, read-only server that continuously receives WAL updates from the primary.
For a deeper understanding of how WAL works, check out the official PostgreSQL docs.
Primary server
In PostgreSQL replication, the primary server handles all the writes. After a transaction is saved, it logs the changes in the Write-Ahead Log (WAL).
These logs are then sent to one or more replicas, which use them to stay updated. The process is asynchronous, meaning the primary doesn’t wait for the replicas before confirming the transaction to the client. It sends the data after finishing the changes on its own side.
Secondary server
The replica server is a read-only copy of the primary that receives WAL data in real time. You can connect one or more replicas to a single primary server. Under normal conditions, replicas handle read-only queries, helping reduce the load on the primary. In case of a failure, a replica can be promoted to act as the new primary to maintain high availability.
Postgres Replication with FerretDB Architecture
Replication in FerretDB starts with a primary PostgreSQL instance that manages all write operations. Read replicas, also running PostgreSQL, sync with the primary via streaming replication, ensuring that all replicas have up-to-date data without impacting the primary’s write performance. Here’s an example of a replication setup in FerretDB:
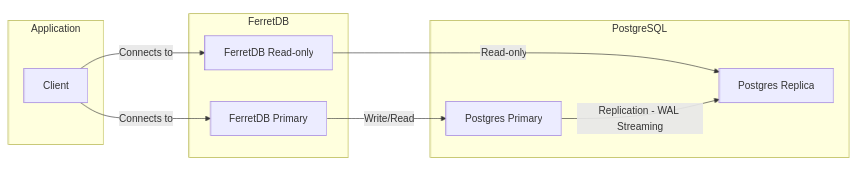
FerretDB consists of a primary instance that handles both reads and writes, and read-only replicas that only serve read requests. If multiple replicas are configured, read traffic can be distributed across them, reducing latency and improving performance.
Next Steps
- Deploy FerretDB ReplicaSet using KubeDB.
- Detail concepts of FerretDB object.
- Detail concepts of FerretDBVersion object.
- Want to hack on KubeDB? Check our contribution guidelines.
NB: The images in this page are taken from FerretDB website.